So lately a though started to form in my mind that has been there for quite some time but due to environment has become more and more dominant in my head. A lot of times when I see people dealing with bugs, their first reaction is “This can’t be a problem with my code!”. Though understandable to some point, this is of course bad for the project (and for the team moral). Before long you have bugs floating from one to another, being closed, reopened again and start that nasty circle all over. Most of you will probably know what kind of bugs I’m talking about. So what to do about this? The answer is simple: Be what most of you have been trained to be! Be a scientist! I’ve come about this very intriguing graphic a few days ago:
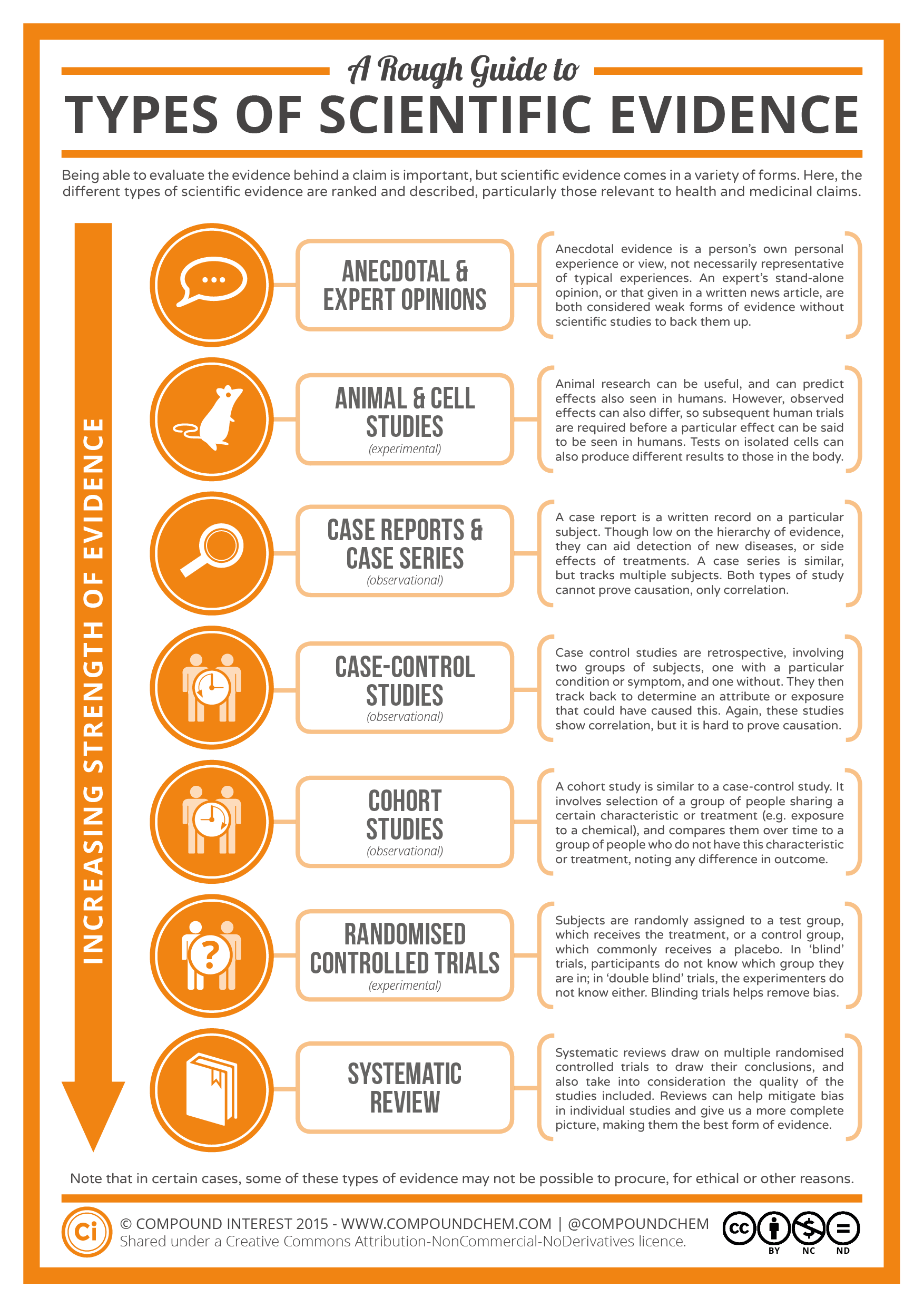
Though technically oriented towards medical students this pictures pretty clearly what evidence you can trust easily and what might be a bit fishy. The first thing that catches the eye is that expert opinions are lowest in the list of trustworthy evidence. In other words: The phrase “This can’t be a problem with my code!” said by no matter how much of an expert is basically worthless when it comes to fixing bugs using the scientific approach. Event a hint where the problem may lay is to be regarded as such.. a hint and no more. Especially if you tell yourself that you can not be the origin of that bug always remind yourself that you can’t be sure unless proven right.
The next step on the list is an experimental approach. This is what you’ll see most in code debugging and bug hunting. Changing values or code and see how it reacts to that changes and then extrapolate from that reaction. Though most people would guess this to be a good approach it really is not. Because this way all you get is more data and most of the times more puzzles instead of solutions.There are a million things that can go wrong using this approach. The code might be time critical and only fail if run without stopping by the debugger. Values might be different using a debugging approach. And last but not least: you might simply run your debugging code on different hardware then the real thing.
The next three steps are basically only good for data collection and finding clues as to where the bug may lay. Sometimes this gives you a really good insight and helps you track the problem faster. But normally this would be the job of the QA department. They are responsible to find a way to reproduce the bug and include that report in their bug report. In 90% of the cases we will be writing deterministic software. Meaning: even if we use some kind of weak random generation using predefined seed, the software will always behave the same way when run on the same hardware and giving the same input. If it doesn’t (and believe me thats really hard to prove) then your hardware is broken. So as long as you have not proven your hardware broken and you are sure your program is deterministic, there is always a way to find reproduction steps. And once you have those you’re on a good path.
Which leaves the last two possibilities. The first one being randomized tests (which is might or might not be possible depending on your software and the way you input data) and the last one being a scientific approached review of the code.
Randomized tests are a good subject to be done automatically by your build servers. They can find bugs and you’ll always have the input data that generated those bugs (which makes finding reproduction steps pretty easy). Depending on your program this might be pretty hard to achieve, however you should at least plan in some automated testing before you even begin to write code. In an optimum case you even have the whole continuous deployment pipeline ready to use before you even start to write a single class.
After you’ve done all this and moved through all the fact finding steps you should have a pretty fair idea where your bug is hiding. If not. Start from the beginning. After all: science means that you are looking for the truth and not “your idea of the truth”. So don’t start bug hunting trying to prove it is not your code that is broken. Start bug hunting trying to prove what code is broken. If it turns out it wasn’t your stuff, all the better. Comment the bug and send it along to the code owner. And if it turned out that you did some really bad stuff: Thank god you found it. Every truth is god. And if you learn from your (or from others) mistake it will not happen again.
So once you have all the information and know where to look, start reviewing your code. I like to do this by stepping through it with a debugger and look at what I’ve really got. More often then not the data I see is not what I expected and I can find the problem really quickly. Sometimes its hard to track where that data is coming from. But at least now you know whats causing the symptoms. If you have proven that its not your code that causes the problem, but the data that comes in from somewhere else, its ok to collect all the infos in the bug report and pass it on to the person you think knows that code the best. After all he might be able to given an expert opinion :-P.